
Breaking the AI Memory Wall: The $100M Shift from GPU Scarcity to Memory-Centric Computing
Executive Summary
As the AI industry confronts exponential growth, the primary scaling constraint has shifted from GPU availability to the 'Memory Wall'—the widening gap between processing power and memory access. This bottleneck leads to underutilized hardware and spiraling data center CapEx, threatening the economic sustainability of the AI boom. In response, venture capital is increasingly funding 'infrastructure hedges': foundational hardware companies that solve these physical limitations. A leading example is Majestic Labs, which emerged from stealth on November 10, 2025, with over $100 million in funding from firms like Bow Wave Capital and Lux Capital. Founded by veteran silicon executives from Google and Meta, Majestic Labs is developing a new server architecture with custom silicon designed to provide up to 128 TB of memory per server—a 1000x increase over top-tier GPUs. This memory-centric approach aims to deliver over 50x performance gains, drastically reduce the total cost of ownership (TCO) for hyperscalers, and unlock the potential of next-generation AI workloads like large-context models and agentic systems.
1. The Real Bottleneck—Memory, Not GPUs
For years, the narrative of AI progress has been synonymous with the race for more powerful GPUs. But a more fundamental AI scaling constraint is now taking center stage: the Memory Bottleneck. This "Memory Wall" describes the ever-widening performance gap between the speed of processors and the ability of memory systems to supply them with data. While the computational power (FLOPS) of AI hardware has scaled exponentially, memory bandwidth has lagged significantly, creating a chasm that leaves the world's most powerful chips starved for data and idling for over 50% of their cycles.
Background Metrics Driving the "Memory Wall"
The divergence is stark. Over the past two decades, the peak compute performance of server hardware has scaled at a rate of 3.0x every two years. In contrast, DRAM bandwidth has grown at only 1.6x and interconnect bandwidth at a mere 1.4x over the same period.
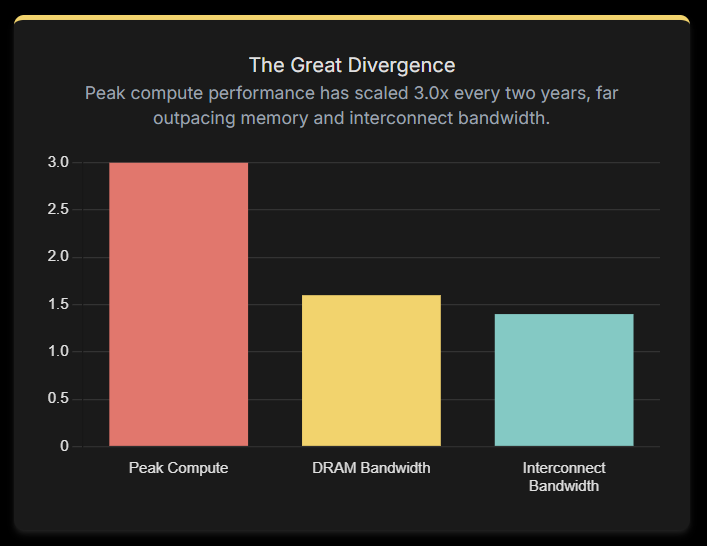
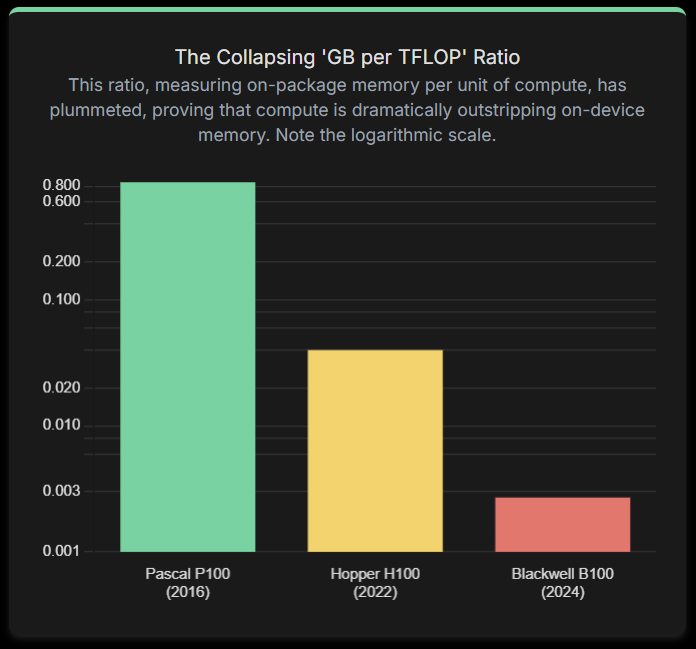
This imbalance is the core of the Memory Bottleneck.This is most evident in the plummeting 'GB per TFLOP' ratio, which measures how much on-package memory is available for each unit of compute. This ratio has collapsed, signaling that compute capabilities are dramatically outstripping on-device memory.
Why It Matters for AI Workloads
This isn't just a theoretical problem; it has a direct impact on performance and cost. For today's most demanding AI workloads—such as Large Language Models (LLMs) with long context windows, agentic AI systems, and graph neural networks — performance is limited by memory, not raw compute. The Key-Value (KV) cache, which stores attention states for every token in a sequence, grows linearly and can quickly consume all available GPU memory. For a Llama-2-7B model, a 28,000-token sequence requires ~14GB for the KV cache, the same amount needed for the model's weights. This forces powerful GPUs to sit idle while waiting for data, wasting up to 60% of their time and energy.
2. Economic Fallout—CapEx and TCO Under Siege
The Memory Bottleneck is not just a technical issue; it's an economic crisis in the making for the AI industry. The inefficiency it creates directly inflates Data Center CapEx and Total Cost of Ownership (TCO), threatening the long-term financial viability of the AI boom.
Hyperscaler Spend Trajectory
Hyperscalers are projected to spend over a trillion dollars on CapEx by 2027, with a growing focus on efficienty. Microsoft expects its capital expenditures to grow from $64.6 billion in fiscal 2025 to a potential $93.7 billion in fiscal 2026, driven by plans to double its data center scale. A huge portion of this spending is a direct result of the memory wall. With memory accounting for up to 50% of a server's bill of materials and HBM prices rising, companies are forced to overprovision expensive GPUs just to aggregate enough memory, a deeply inefficient strategy.
Financial Levers of Memory-Centric Consolidation
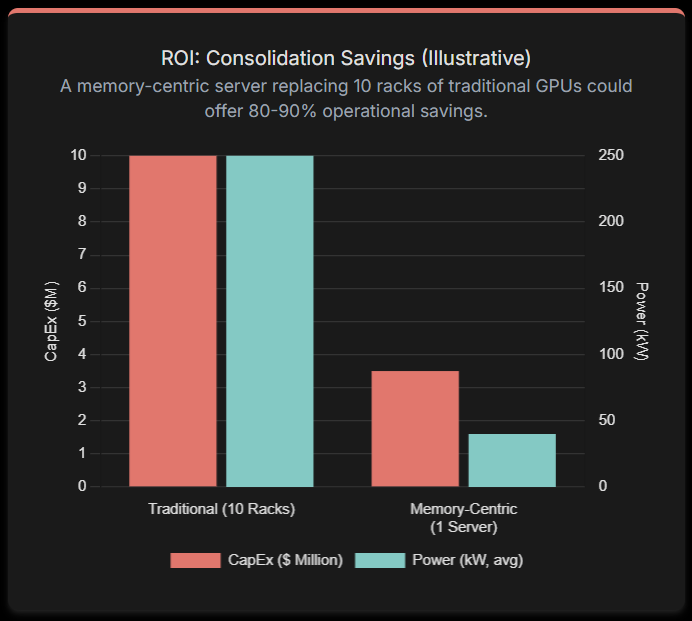
This is where new AI compute hardware solutions like Majestic Labs come in. By radically consolidating infrastructure, they offer a direct path to reducing both CapEx and TCO. Majestic Labs claims a single one of its servers can replace ten or more racks of today's advanced servers.
3. Case Study: Majestic Labs' $100M Moon Shot
On November 10, 2025, Majestic Labs emerged from stealth mode with over $100 million in financing to redefine AI infrastructure. The company's mission is to solve a core bottleneck in advanced AI data centers known as the "memory wall".The startup was founded by a team of veteran silicon executives from Google and Meta:
Ofer Shacham
Sha Rabii
Masumi Reynders
The trio previously worked together leading silicon design teams at both Meta and Google. They are now proposing a radical overhaul of AI server architecture.Majestic Labs is developing next-generation servers with a patent-pending silicon design. This new architecture promises to deliver up to 1,000 times the memory capacity of a top-of-the-line GPU for AI workloads. This leap in memory capacity is designed to address the rapidly growing computational demands of modern AI systems.
Funding Timeline & Investor Signaling
The significant funding signals strong investor confidence in Majestic's architectural disruption. The financing was led by prominent firms known for deep-tech bets, positioning this as a strategic "infrastructure hedge" for the AI era.
Architectural Breakthrough
Majestic Labs' core innovation is a new AI server architecture, built from the ground up with proprietary, patent-pending custom silicon. The system features a custom accelerator and a memory interface chip that disaggregate memory from compute. This design allows them to deliver up to 128 TB of high-bandwidth memory per server—a claimed 1000x increase over a top-tier GPU. The company claims this will unlock over50x performance gains while slashing power consumption.
Execution Risks & Mitigations
The path is not without risk. Developing custom silicon is capital-intensive, and competing with entrenched giants like NVIDIA is a monumental task. Furthermore, with prototypes not expected until2027, the company faces a long road to revenue. However, the founding team's proven track record of shipping hundreds of millions of chips at Google and Meta provides a powerful mitigation against execution risk.
4. Competitive Landscape—Scale-OUT Titans vs Scale-UP Rebels
The race to solve the Memory Bottleneck is creating two distinct strategic camps. The incumbents are focused on "scaling out," while a new wave of startups is pioneering "scaling up."
GPU Platform Roadmaps (NVIDIA, AMD, Google, Intel)
The incumbent approach involves connecting thousands of individual GPUs with high-speed interconnects to create massive, rack-scale systems. While this achieves immense total capacity, it comes at a staggering cost in terms of power, complexity, and latency.
Start-up Ecosystem Map
In contrast, startups like Majestic Labs are "scaling up" the node itself. By packing up to128 TB of memory into asingle server, they offer vastly superior memory density. This promises lower latency for communication within a unified memory pool, as data doesn't need to traverse a complex network fabric. This full-system architectural approach is a key differentiator from other players who may focus only on component-level solutions like memory disaggregation or compute-in-memory.
5. Standards Tailwinds—CXL, UALink, UCIe
The move toward memory-centric architectures is not happening in a vacuum. A maturing ecosystem of open standards is lowering the risk of adoption and preventing vendor lock-in.
CXL (Compute Express Link): This is the cornerstone protocol for memory expansion, pooling, and sharing. The CXL 3.2 specification was released on December 3, 2024, focusing on enterprise readiness and security. With CXL projected to be in 99% of servers by 2028, it provides a standardized path for building large-scale, disaggregated memory systems.
PCIe (Peripheral Component Interconnect Express): As the physical layer for CXL, PCIe's roadmap is critical. The PCIe 7.0 specification, released in June 2025, doubles the data rate to 128 GT/s, ensuring the transport layer won't become a bottleneck.
UALink & UEC: For accelerator-to-accelerator communication, open standards like UALink (Ultra Accelerator Link) and UEC (Ultra Ethernet Consortium) are emerging to compete with proprietary solutions like NVIDIA's NVLink, providing an open fabric for compute elements to access vast CXL memory pools.
UCIe (Universal Chiplet Interconnect Express): This standard allows companies to integrate best-in-class chiplets from different vendors into a single package, accelerating the development of custom silicon like that used by Majestic Labs.
6. Sustainability & Energy Impact
The memory wall is a primary driver of the AI industry's ballooning energy consumption and environmental footprint. Tackling this AI scaling constraint is now a top priority for meeting corporate sustainability goals.
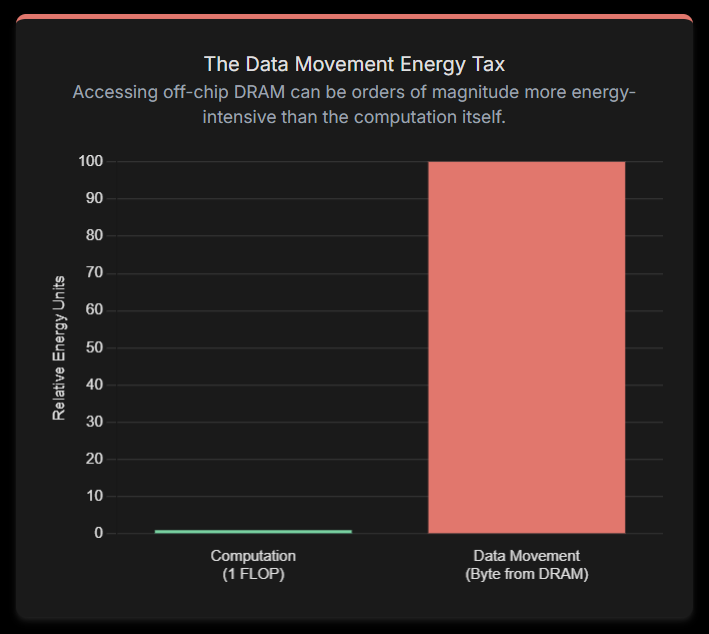
Data Movement Energy Tax
The energy cost of moving data is now a dominant factor in total power consumption. Accessing a single byte from off-chip DRAM can be orders of magnitude more energy-intensive than the actual computation.
This inefficiency is compounded by the need to overprovision power-hungry GPUs, with a single NVIDIA DGX H100 server drawing up to 10.2 kW. Memory subsystems alone can account for up to 50% of total system power.
Consolidation Payoff
Memory-centric designs offer a powerful solution. By consolidating the capacity of 10 racks into a single server, Majestic Labs claims it can "substantially slash power consumption, reduce cooling costs, and decrease the overall data center footprint." This is critical as AI pushes rack densities beyond 100 kW, forcing a costly transition to liquid cooling. These efficiency gains align directly with the public sustainability targets of hyperscalers like Google, Microsoft, and AWS, whose carbon emissions have risen dramatically due to AI's growth.
7. Investor Playbook—Infrastructure Hedges for Durable Alpha
For investors tracking AI infrastructure investment, the shift toward memory-centric hardware represents a move toward more defensible, long-term value. While the AI application layer is volatile, the underlying infrastructure is indispensable—the "picks and shovels" of the AI gold rush.
Risk/Reward Matrix: Hardware vs. Application Start-ups
Investing in foundational hardware carries a different risk/return profile than betting on the next hot AI application.
Exit Precedents & Scenarios
Potential exit paths for these infrastructure plays are well-established and lucrative. The 2024 IPO of Astera Labs, a CXL connectivity provider, demonstrated strong public market appetite for companies solving AI infrastructure bottlenecks. Alternatively, strategic acquisition by platform giants like NVIDIA, AMD, or hyperscalers looking to integrate critical technology remains a primary exit strategy.
8. Failure Modes & Watch-Fors
Despite the promise, the path for memory-centric hardware startups is fraught with peril. High silicon development costs, the challenge of building a software ecosystem to rival incumbents, and the risk of standards drifting can derail even the most promising ventures. The history of the semiconductor industry is littered with cautionary tales, from the market fade of Intel's Optane to periodic supply shocks in the HBM market. To succeed, companies like Majestic Labs must secure phased funding tied to tape-out milestones, forge early partnerships with independent software vendors (ISVs), and pursue a multi-foundry strategy to mitigate supply chain risks.
9. Action Plan for Stakeholders
For Cloud Buyers
The emergence of memory-centric architectures requires a shift in procurement strategy. Instead of focusing solely on GPU counts, evaluate pilot workloads (especially long-context LLMs) on early evaluation units from companies like Majestic Labs. Negotiate TCO-based pricing models that account for the significant savings in power, cooling, and data center footprint.
For VCs/PE
The data suggests a strategic allocation to infrastructure is warranted. Consider dedicating 15-20% of AI-focused funds to "infrastructure hedges" that provide bottleneck relief. Structure investments with milestone-based tranches tied to silicon tape-out and customer validation to de-risk the long development cycles.
For Policy & Sustainability Leads
The energy savings from memory-led efficiency are substantial. Work to tie power draw reductions to green financing incentives and corporate sustainability mandates. Championing open standards like CXL and UALink can also accelerate the adoption of more energy-efficient architectures, helping the industry scale responsibly.
10. Conclusion—The Memory-Centric Future
The AI revolution is running headfirst into a wall—not of silicon, but of memory. The relentless growth in model size has made the Memory Bottleneck the single greatest threat to the performance, cost, and sustainability of artificial intelligence. The era of simply adding more GPUs is proving to be an economically and environmentally unsustainable path. The more than$100 million invested in Majestic Labs is a clear signal that smart capital is shifting its focus from raw compute to memory-centric solutions. By re-architecting the server from the ground up to prioritize memory capacity and bandwidth, companies like Majestic are not just building faster hardware; they are creating a more efficient and economically viable foundation for the next decade of AI. For investors, operators, and builders in the AI ecosystem, the message is clear: the future of AI won't be measured in just FLOPS, but in gigabytes per watt.
Recommended:
Nov 19
Top 20 VCs Investing in AI in 2025 (The Active List)
Nov 17
Top 5 AI Investment Themes for 2026 (Backed by $216 Billion)
Nov 15
Top AI Investors 2025 YTD by Dollars and Deal Count
Nov 14
AI Funding Recap Nov 10–14, 2025: $5.02B Across 58 Deals
Nov 13:
Is the AI Bubble 2025 Popping? Decoding Today's $17.3B Mega-Rounds Amid Valuation Red Flags
Nov 11:
Breaking the AI Memory Wall: The $100M Shift from GPU Scarcity to Memory-Centric Computing
Nov 10:
The Geopolitics, Infrastructure, and Commercialization Dynamics of the Global AI Ecosystem
The AI Funding Barbell: What November 10th's $629M Reveals About the New Market